
Ryan Le
Gen AI Manager
Coding, STEM & Engineering, Physical AI & Robotics













LQA delivers training datasets for computer vision models, enabling accurate object detection, segmentation, and scene understanding through image and video annotation.
LQA develops NLP training data to power language models and conversational AI systems, including text classification, named entity recognition, sentiment analysis, and multi-turn dialogue datasets.
LQA provides multimodal datasets combining text, images, audio, and video to support AI systems that require cross-modal understanding and contextual reasoning.
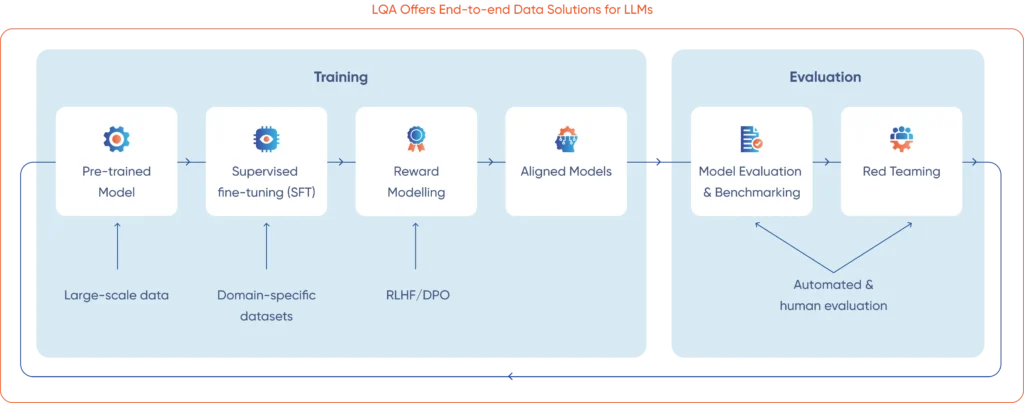
LQA creates datasets for training process and fine-tuning LLMs, including instruction tuning, prompt-response generation, and evaluation datasets to improve model accuracy and alignment.
LQA delivers domain-specific datasets for advanced AI systems, including physical AI, autonomous systems, coding agents, and STEM applications requiring complex environments and high-precision data.
LQA delivers human feedback and evaluation datasets for LLM alignment and post-training optimization, including RLHF, preference ranking, response evaluation, safety assessments, hallucination detection, and model benchmarking.


Requirement Analysis
LQA works closely with clients to define business goals, data sources, and LLM fine-tuning requirements, covering model scope, domain needs, training methods, evaluation criteria, and cost considerations.

Team Setup
A dedicated team of experts are assembled and aligned through onboarding sessions, ensuring consistency in data preparation, annotation standards, and execution from day one.

Pilot & Validation
LQA runs pilot tasks to validate workflows, refine guidelines, and address edge cases early, incorporating feedback to ensure alignment with expected model performance.

Full-scale Execution
We scale LLM training and fine-tuning pipelines with continuous quality control, structured evaluation, and iterative feedback loops to maintain accuracy and consistency.

Improvement
We monitor performance, identify gaps, and optimize datasets and workflows over time, ensuring your LLM systems improve in reliability, safety, and real-world performance.

教育・エドテック
理解度に応じたAI家庭教師の構築、テスト問題や教材の自動生成、記述式回答のリアルタイムな添削とフィードバックを、LLMを用いてサポートします。これにより、生徒一人ひとりに最適化された学習体験を提供し、教育者の業務負担を軽減します。
LQA defines project scope, model requirements, data types, and success metrics, aligning datasets with business goals and the overall AI model training process.
LQA assembles and onboards dedicated teams with clear guidelines, annotation standards, and workflows to ensure consistency from the start.
LQA validates data pipelines through pilot tasks, refines annotation guidelines, and addresses edge cases to ensure alignment with expected model performance.
Our team scales AI training data pipelines with continuous quality control, structured evaluation, and feedback-driven loops.
Our experts optimize datasets and workflows through ongoing evaluation, error analysis, and data-centric iteration, thereby improving model accuracy and reliability over time.






























Vietnamese

English

Russian

Mandarin Chinese

Cantonese

Japanese

Korean

Malay

Indonesian

Thai

Lao

Hindi

Arabic

French

German

Spanish

Portuguese

Italian

Bulgarian

Hungarian
Engineering
Civil Engineering
Law
Finance
Accounting
Economics
Mathematics
Computer Science
Medicine
Psychology
Physics
Healthcare
Chemistry
Biology
Astronomy
Biotechnology
Bioinformatics
Teaching
Linguistics
Religion
Language Arts
Music
Philosophy
History
Performing Arts
Robotics Engineers
Computer Scientists
Software Engineers
Systems Architects
Data Engineers
AI/ML Researchers
Financial Analysts
Accountants
Auditors
Economists
Investment Bankers
Risk Managers
Psychologists
Sociologists
Political Scientists
Administrators
Scientists
Mathematicians
Photographers
Screenwriters
VFX Supervisors
Cinematographers
Art Directors
Creative Directors
Animation Directors
3D Modelers
Sound Designers
Audio Engineers
Music Composers
Voice Directors










Deliver consistent AI training data through structured evaluation, strict quality control, and human-in-the-loop workflows.

Leverage a global network of experts with diverse backgrounds, from linguists and engineers to domain specialists, to ensure quality.

Support global AI deployment with multilingual training data across languages, regions, and cultural contexts.

Scale AI training data efficiently with flexible engagement models and optimized workflows without compromising quality.

昆虫・幼虫の2Dバウンディングボックス・アノテーション
イタリアの大学による政府出資の昆虫・幼虫・感染症媒介研究プロジェクトを支援。昆虫個体群の早期発見と分析精度の向上により、感染症拡大防止に向けた研究の加速に貢献しました。
詳細を見る 農業画像セグメンテーションの自動化支援
デジタルツインおよびLiDARソリューションを展開する韓国企業向け。未加工の膨大な農業画像データに対し、極めて短期間で高品質なセグメンテーション・アノテーションを提供し、プロジェクトの迅速な立ち上げを実現しました。
詳細を見る 小売店舗における商品(SKU)の2Dバウンディングボックス
小売・スーパーマーケット環境における商品(SKU)検知AIの学習データ構築プロジェクト。棚にある商品の正確な認識・自動識別を可能にし、在庫管理システムの精度向上を支援しました。
詳細を見る 自動運転向けポリゴン・アノテーションによる物体分類
自動運転(AV)技術を牽引する韓国の知覚ソフトウェア企業向け。世界中から収集された膨大な走行データに対し、高精度な2Dポリゴンアノテーションを実施し、安全性に直結する物体識別精度の向上を支えています。
4Dデジタルツインプラットフォーム向け建築図面ラベリング
建設業界のDXを推進する4Dデジタルツインプラットフォーム向け。複雑な建築図面や技術データのラベリングを行い、設計データと現場の進捗をリアルタイムに同期させる高度な可視化を支援しました。
詳細を見る AIトレーニング向けアプリ操作データの収集・記録
人間とAIの相互作用を研究する米国の研究所向け。AIがより人間らしく直感的にデジタルプラットフォームを操作できるよう、リアリティのある膨大なユーザー操作ログとインタラクションデータを収集・提供しました。
詳細を見る ハンズフリー操作AI向けの視線データ収集
視線のみでデバイスを操作する次世代インターフェースを開発するイスラエルの技術企業向け。手動入力不要のコミュニケーション実現に向け、多様な条件下での大規模な視線データの収集・構造化を行いました。
詳細を見る 建設現場の安全監視システム向け2Dバウンディングボックス
建設現場の安全モニタリングを専門とする韓国のAI企業向け。作業員や危険エリア、安全装備の着用状況をリアルタイムで検知するコンピュータビジョン・システムの構築をデータ側面から強力にバックアップしました。
物流現場のフォークリフト・パレット間動作のキーポイント抽出
スマート倉庫や製造現場のオペレーション監視システム開発。フォークリフトとパレットの相互作用を正確に捉える2Dキーポイントアノテーションを提供し、作業の安全性向上とワークフローの最適化を実現しました。












