フィジカルAIとは?仕組み・活用事例・生成AIとの違いをわかりやすく解説
AIの世界は今、デジタル空間上の知能から、物理世界で稼働するシステムへと急速に進化しています。テキスト、画像、コードなどを生成する生成AIが大きな注目を集める一方で、企業は「理解する」だけでなく、現実世界で行動するソリューションを求めています。この変化の背景には、製造、物流、モビリティなど、あらゆる産業において自動化、効率化、そしてリアルタイムな意思決定へのニーズがかつてないほど高まっているという現状があります。
同時に、日本では労働力不足、高齢化、運営コストの上昇といった構造的な課題が、この移行を加速させています。現場での作業のあり方を見直さざるを得ない状況下で、デジタル業務だけでなく、工場やサプライチェーンといった現場の物理的な作業を自動化する技術が切実に求められているのです。
こうした文脈の中で、次世代のAIとして注目されているのがフィジカルAIです。本記事では、フィジカルAIの定義、仕組み、生成AIとの決定的な違い、そしてなぜ今、ビジネスにおいて不可欠な存在となっているのかを解説します。
フィジカルAIとは何か?
フィジカルAIの定義
フィジカルAIとは物理的な世界を認識し、推論し、実際に行動するように設計されたAIシステムのことです。
予測やコンテンツ生成といったデジタルデータの処理を主とする従来のAIとは異なり、フィジカルAIは、センサー、ロボット、組み込みシステムといったハードウェアを通じて、現実世界の環境と直接やり取りを行います。
その核心は、環境データの収集(カメラ、LiDAR、IoTデバイス等)、データの解釈、意思決定、そしてリアルタイムでの実行という一連の流れを連続的に繰り返す点にあります。このため、自動運転車や産業用ロボット、スマート物流システムなど、タイミング、精度、適応性が極めて重要となる分野で真価を発揮します。一言で言えば、フィジカルAIは知能と実行の橋渡しを行い、予測不可能な動的な環境下で機械を自律的に動作させる技術です。
生成AIとフィジカルAIの比較
生成AIとフィジカルAIは、どちらも高度な機械学習技術を基盤としていますが、その目的や活動領域は根本的に異なります。それぞれの強みを理解し、どこで価値を発揮するのかを見極めることが重要です。
|
比較項目 |
生成AI |
フィジカルAI |
|
目的 |
知識の生成、変換、拡張 |
物理世界の認識と行動 |
|
主な成果物 |
デジタルコンテンツ(テキスト、画像、コード等) |
物理的な動作(移動、操作、制御) |
|
活動環境 |
デジタル空間 |
現実世界の環境 |
|
データ要件 |
大規模なラベル付き/なしデータセット |
リアルタイムなマルチモーダルデータ、クローズドループの相互作用データ |
|
システム構成 |
基盤モデル(LLM、拡散モデル等) |
AIモデルとセンサー、アクチュエータ、制御システムの統合 |
|
評価基準 |
正確性、整合性、創造性、関連性 |
安全性、信頼性、遅延の少なさ、精度、堅牢性 |
最大の違いは、生成AIの評価軸が主に「情報やコンテンツの質」にあるのに対し、フィジカルAIの評価軸は「予測不可能な環境において、いかに正しく、安全かつ一貫して行動できるか」にあるという点です。
フィジカルAIの構築がより複雑である理由はここにあります。生成AIであれば画面上で「不適切な回答」が出るだけで済みますが、フィジカルAIの場合、小さなエラーが現実世界の事故や業務停止という大きなリスクに直結するためです。
フィジカルAIを支える基盤技術
フィジカルAIシステムは、単一のモデルで構成されているわけではありません。現実世界で確実に動作させるためには、複数の技術が緊密に統合される必要があります。これら基盤となる要素が連携することで、デジタル上の知能と、物理的な実行の間のギャップを埋めることができるのです。

フィジカルAIを支える基盤技術
認識と現実世界モデル
高度な認識とセンサーシステム
フィジカルAIの最前線にあるのは、環境を把握する能力です。これは、カメラ、LiDAR、レーダー、IoTデバイスなどのセンサーの組み合わせによって実現されます。
これらのセンサーがリアルタイムのマルチモーダルデータ(視覚的、空間的、時には触覚的な情報)を収集することで、システムは周囲の環境を高精度に理解することが可能になります。センサーの質と多様性が、システムの精度と応答性に直結します。
現実世界モデルと物理シミュレーションAI
適切な意思決定を行うために、フィジカルAIは「デジタルツイン」や「シミュレーションモデル」と呼ばれる現実世界の表現を活用します。これらのモデルは現実の状況を再現し、システムが実際に行動を起こす前に結果を予測したり、シナリオをテストしたり、行動を最適化したりすることを可能にします。試行錯誤がコストや安全性の面で許されないような、複雑かつ高リスクな環境において、この現実世界モデルは極めて重要です。
知能と学習
学習アルゴリズムと制御
フィジカルAIシステムは、学習と適応制御を通じて絶えず改善を繰り返します。強化学習、模倣学習、モデル予測制御といった手法により、システムは環境からのフィードバックに基づいて行動を最適化します。静的なモデルとは異なり、これらのシステムは、学習と実行が密接に結びついたクローズドループ環境で動作します。
実行とシステムインフラ
ロボティクスとアクチュエーション
決定事項を現実世界に反映させるには、ロボットの機動力と駆動技術が不可欠です。これには、移動を可能にする機械システムやモーター、オブジェクトを操作するための制御インターフェースなどが含まれます。特に状況が刻々と変化する環境では、その精度、安定性、適応性が重要となります。
オンデバイスAI
現実世界でのオペレーションには、低遅延の意思決定が不可欠です。エッジAIにより、データ処理や推論をデバイス上、あるいはデータ発生源の近くで行うことで、集中型システムへの依存度を低減できます。これは、遅延が致命的な失敗につながる恐れのある自動運転や産業オートメーションにおいて特に重要です。
クラウドとエッジの統合
フィジカルAIシステムには、多くの場合、高い計算能力と低遅延なレスポンスの両方が求められます。
クラウドコンピューティングは大規模なデータ処理、モデルトレーニング、システム全体の連携を担い、エッジコンピューティングは物理環境に近い場所でのリアルタイムな意思決定を担います。このクラウドとエッジの統合により、パフォーマンス、スケーラビリティ、そして応答性のバランスが確保されます。
データおよび運用インフラ
あらゆるフィジカルAIシステムの背後には、強固なデータおよび運用基盤が存在します。これには、データの収集、アノテーション、シミュレーションデータの生成、モデルのデプロイを行うためのパイプラインが含まれます。現実世界のデータを扱うことはデジタルデータセットを扱うよりもはるかに複雑であり、システムの性能を維持するために、継続的な更新、監視、検証が求められます。
人とロボットの協調システム
多くの現実的なアプリケーションにおいて、フィジカルAIは孤立して動くのではなく、人間と共に作業します。人とロボットの協調技術は、安全プロトコル、直感的なインターフェース、支援的知能などの要素を取り入れ、安全かつ効率的な相互作用を保証します。これは、依然として人間による監督が不可欠な製造業や医療現場といった分野で特に重要となります。
フィジカルAIの仕組み
従来の入力に対して出力を返すという線形的なAIシステムとは異なり、フィジカルAIは継続的なクローズドループシステムとして機能します。一度きりのアウトプットで終わるのではなく、リアルタイムのフィードバックに基づいて理解と行動を絶えず更新することで、工場、公道、倉庫といった複雑な環境下でも確実な動作を実現します。
フィジカルAIがどのように機能するのか、5つのステップで解説します。

フィジカルAIの仕組み
ステップ1:リアルタイムな状態把握
プロセスは、環境の現在の状態を連続的に捉えることから始まります。ここでは単なる生データの収集にとどまらず、物体の位置、システムの状態、環境の変化など、「今、何が起きているのか」というスナップショットを常に最新の状態に保つことが重視されます。このリアルタイムな認識能力こそが、後の意思決定の成否を分ける鍵となります。
ステップ2:環境理解と状態推定
次に、入力されたデータを環境の構造化された表現へと変換します。具体的には、関連する物体の特定、位置情報の推定、空間的な相互関係の把握などを行います。単に「見る」だけでなく、現在の状況を「実行可能な形」として確実かつ正確に把握することがこのステップの目的です。
ステップ3:状況に応じた意思決定と計画
解釈された環境情報に基づき、システムは最適な行動を選択します。ここでは、安全性、時間、効率性といった制約条件を考慮しながら、考えられる複数の結果を評価し、最適な実行計画を立てます。動的な環境下では、このプロセスを一度だけでなく、継続的に繰り返さなければなりません。
ステップ4:物理的な制約下での実行
計画された行動を現実世界で実行に移します。デジタルシステムとは異なり、ここでは動作のダイナミクス、摩擦、タイミングといった「物理的な制約」を考慮する必要があります。小さなミスが現実世界での重大な事故や損失につながる可能性があるため、極めて高い精度と安定性が求められます。
ステップ5:フィードバックによる適応
実行後、システムは即座に期待値と実際の結果を比較し、成果を評価します。このフィードバックは、将来の意思決定を調整し、性能を向上させるために活用されます。この継続的なループを回すことで、フィジカルAIは現実世界の変動にさらされても、より適応的で、堅牢で、効率的なシステムへと進化していきます。
日本におけるフィジカルAI導入の重要性
現在、日本は構造的な課題と技術革新の交差点に立っています。産業界において生産性と効率性の維持・向上が急務となる中、従来のアプローチには限界が見え始めています。こうした状況下において、フィジカルAIは単なる新しいテクノロジーではなく、日本企業が生き残るための「戦略的必須要件」となりつつあります。

日本におけるフィジカルAI導入の重要性
労働力不足への対応
日本は少子高齢化に伴い、先進国の中でも特に深刻な労働力不足に直面しています。特に製造、物流、建設といった物理的な作業に依存する業界では、その影響が顕著です。
フィジカルAIは、これまで人手に頼らざるを得なかったタスクを機械に代替させることで、この課題に対する現実的な解決策を提示します。単なる単純作業の自動化にとどまらず、労働力の確保状況に依存しない、持続可能かつ安定的なオペレーションを実現します。これにより企業は、労働力不足のリスクを緩和しながら、生産性を維持・向上させることが可能となります。
DXの次のステージとしての役割
多くの日本企業がDXを推進していますが、その焦点は依然としてデータのデジタル化やバックオフィス業務の最適化に留まっているケースが多く見受けられます。
しかし、日本企業の価値創造の源泉は、依然として「現場(工場、倉庫、サプライチェーン)」にあります。フィジカルAIは、その知能を物理的な現場環境へと拡張することで、DXを次の段階へと引き上げます。これにより企業は、データに基づく意思決定から、リアルタイムでインサイトを即座に実行に移す自律的なオペレーションへと進化することができます。これは、エンドツーエンドの業務効率化を実現するために不可欠なプロセスです。
現場力を活かす産業構造への適応
日本の産業の強みは、古くから現場に根ざしてきました。しかし、現場作業の多くは依然として属人的な熟練技術や手作業に依存しており、標準化やスケールアップが困難であるという課題を抱えています。
フィジカルAIは、熟練の職人技や現場のノウハウをデータとして捉え、モデル化し、自動化することで、このギャップを埋める役割を果たします。暗黙知をデータ駆動型のシステムに変換することで、業務のバラつきを抑え、一貫性を高めるとともに、チームや拠点間での円滑な技術継承を可能にします。これは、労働環境が激しく変化する中で、長期的な卓越した運営能力を維持するために極めて重要です。
グローバル競争力の強化
AIやロボティクス分野において米国や中国を中心とした国際的な競争が激化する中、日本企業にはオペレーションのさらなる近代化が求められています。
フィジカルAIは、生産性の向上、迅速な意思決定、そして柔軟な生産システムの構築を可能にすることで、日本の競争力を維持・強化する鍵となります。また、世界的に標準となりつつあるスマート工場や自律型物流ネットワークの構築を支援します。フィジカルAIの導入を通じて、日本企業は国内業務の最適化を図るだけでなく、次世代の産業イノベーションを牽引するリーダーとしての地位を築くことができるはずです。
フィジカルAIの主要な活用事例
日本は、ロボット技術や自動化において世界有数の先進市場であり、フィジカルAIを実装・検証するための最適な環境が整っています。人手不足という構造的課題と高い産業技術力を背景に、すでに複数のセクターでフィジカルAIが導入され、確かなビジネス成果を上げ始めています。

フィジカルAIの主要な活用事例
製造業
製造業は、日本においてフィジカルAIが最も成熟し、大きな存在感を示している分野です。日本は長年、産業用ロボットの分野で世界をリードしており、日本のメーカーが世界市場で高いシェアを占めています。
現在、製造業の焦点は、事前にプログラムされた従来の自動化から、刻々と変わる状況に即座に適応できるAI駆動型システムへと移り変わっています。この移行は、より柔軟で知的な生産環境への進化を意味します。
主な活用事例:
- 環境の変化に応じて動作を動的に調整するAIロボット
- センサー、ロボット、リアルタイムデータ処理を統合した「スマートファクトリー」
- コンピュータビジョンを活用した自動外観検査
- 予測保全によるダウンタイムの削減と効率化
物流
Eコマースの拡大と深刻な人手不足を背景に、物流業界ではフィジカルAIの導入が急速に進んでいます。日本の物流自動化市場は大幅な成長が見込まれており、2026年までには100億ドル規模に達すると予測されています。
主な活用事例
インサイト:物流は、業務効率化と労働力不足解消の両面で、フィジカルAIが即座に価値を提供できる最も成長著しい分野の一つです。
自動運転
自動運転は、日本におけるフィジカルAIの最前線であり、特に地方や高齢化が進む地域での移動手段の課題解決において期待されています。完全自動運転の実現に向けた開発が続く中、ナビゲーションや障害物検知、リアルタイムな意思決定を行うAIシステムが、すでに車両に組み込まれ始めています。
主な活用事例
インサイト: 日本の強力な自動車産業と、スマートモビリティ推進に向けた政府のサポートは、日本をこの分野の主要プレーヤーにしています。フィジカルAIは、複雑な現実世界を車両が解釈し、安全に応答することを可能にする、次世代輸送の基盤技術です。
車両のソフトウェア化が進む中で、システムの信頼性と安全性を担保することが極めて重要になります。車載ソフトウェアテストやAI統合戦略など、自動車システムの未来については以下の記事も参考にしてください。
医療ロボット
医療現場では、超高齢社会と介護者不足の解決策として、フィジカルAIが注目を集めています。患者の移動支援、日常生活のケア、病院運営のサポートなどを目的としたAIロボットの開発が進んでいます。
主な活用事例
小売業
小売業は、無人店舗や自動化された店舗の開発を通じて、フィジカルAIの新たな適用領域として浮上しています。これらのシステムは、業務効率の向上と顧客体験の向上の両立を目指しています。
主な活用事例:
インサイト: フィジカルAIは、顧客にストレスのない買い物を体験してもらうと同時に、小売業者が直面する人手不足という制約への対応を支援します。

フィジカルAI導入における課題と解決策
フィジカルAIは大きな可能性を秘めている一方で、現実世界への実装には特有の難しさがあります。デジタル空間だけで完結するAIとは異なり、フィジカルAIは不確実性を伴う動的な環境下で動作し、極めて厳格な安全性と性能が求められるためです。導入を成功させるには、これらの課題を一つひとつ乗り越えることが不可欠です。
データ収集の難しさ
フィジカルAIの最大の障壁の一つが、高品質な現実世界のデータの収集です。デジタルデータとは異なり、フィジカルAIに必要なデータは、多様で予測不可能な環境下でセンサーを通じて収集しなければなりません。このプロセスには時間とコストがかかり、自動運転や産業オペレーションなどのシナリオでは、安全性確保の面でリスクを伴うこともあります。
解決策
多くの組織が、現実世界のデータセットを補完するために「合成データ」や「シミュレーション環境」の活用を進めています。リアルな仮想シナリオを生成することで、物理的な試験に伴うリスクを冒すことなく、データの収集・拡充、エッジケース(例外的な状況)の網羅、モデル学習の加速が可能になります。
安全性の懸念
フィジカルAIシステムが故障すれば、機器の損傷、業務の停止、さらには人身事故など、現実世界での重大な結果を招く恐れがあります。そのため、製造、医療、モビリティといった分野では、安全性が何よりも優先される課題となります。
解決策
リスクを軽減するためには、シミュレーションによる試験と管理された環境下での実証実験を組み合わせた、厳格なテスト・検証フレームワークを導入する必要があります。また、信頼性の高い動作を保証するために、冗長系(予備システム)の構築、フェイルセーフ機構、そして継続的な監視体制の構築が不可欠です。
コストとROI
フィジカルAIシステムの導入には、多くの場合、ハードウェア、インフラ、システム統合に向けた多額の初期投資が必要です。特に従来のシステムから移行しようとしている企業にとって、ROIが見えにくいことが導入を躊躇させる要因となっています。
解決策
小規模なパイロットプロジェクトやPoCから始めるという「段階的なアプローチ」が有効です。これにより、本格的な展開の前に価値を検証することができます。また、労働集約的なプロセスへの自動化など、インパクトの大きい領域に絞って導入することで、測定可能なROIを早期に証明しやすくなります。
汎化の難しさ
フィジカルAIシステムは、異なる環境間での汎化に苦労することが少なくありません。ある環境で学習したモデルが、照明条件やレイアウト、運用状況がわずかに異なる別の環境ではうまく機能しないという問題です。
解決策
汎化性能を高めるには、多様なトレーニングデータ、シミュレーションベースの学習、そして適応型アルゴリズムの組み合わせが求められます。ドメインランダム化(環境の多様性を学習させる手法)や強化学習などの技術を用いることで、システムは環境の変動をより効果的に扱えるようになり、未知の環境にも時間をかけて適応できるようになります。
フィジカルAI開発の重要要素
これらの課題を克服し、堅牢なシステムを構築するためには、いくつかの重要な要素が開発プロセスにおいて不可欠です。

フィジカルAI開発の重要要素
合成データ
合成データは、フィジカルAIをスケーリングするための基盤技術となっています。現実世界の条件を模した仮想環境を作成することで、組織はラベル付きの高品質なデータを効率的に生成できます。これは特に、現実では再現が困難な希少な状況や危険なシナリオをシミュレートする際に非常に有用です。実データと合成データを組み合わせることで、モデルの性能と堅牢性は飛躍的に向上します。
強化学習
強化学習は、フィジカルAIが対話を通じて学習するために広く活用されています。環境から継続的にフィードバックを受け取ることで、AIエージェントは時間の経過とともに自身の行動を最適化していきます。特にロボット制御や自律走行など、試行錯誤を通じて性能を向上させる必要がある、一連の意思決定が求められるタスクにおいて、強化学習は極めて効果的です。
実装手法
フィジカルAIの導入を成功させるには、構造化された実装戦略が必要です。主に以下の要素が挙げられます。
- シミュレーションファースト開発:現実世界にデプロイする前に、まずは仮想環境でモデルのテストとトレーニングを行う。
- 段階的なロールアウト:管理された環境からスタートし、徐々に複雑なシナリオへと拡大していく。
- 人間参加型(Human-in-the-loop)システム:AIによる自動化と人間の監視を組み合わせ、安全性と信頼性を担保する。
こうした手法を採用することで、組織はリスクを低減し、コストを抑制しながら、実験段階から実用段階への移行を加速させることができます。
開発からデプロイへ:データとテストの重要性
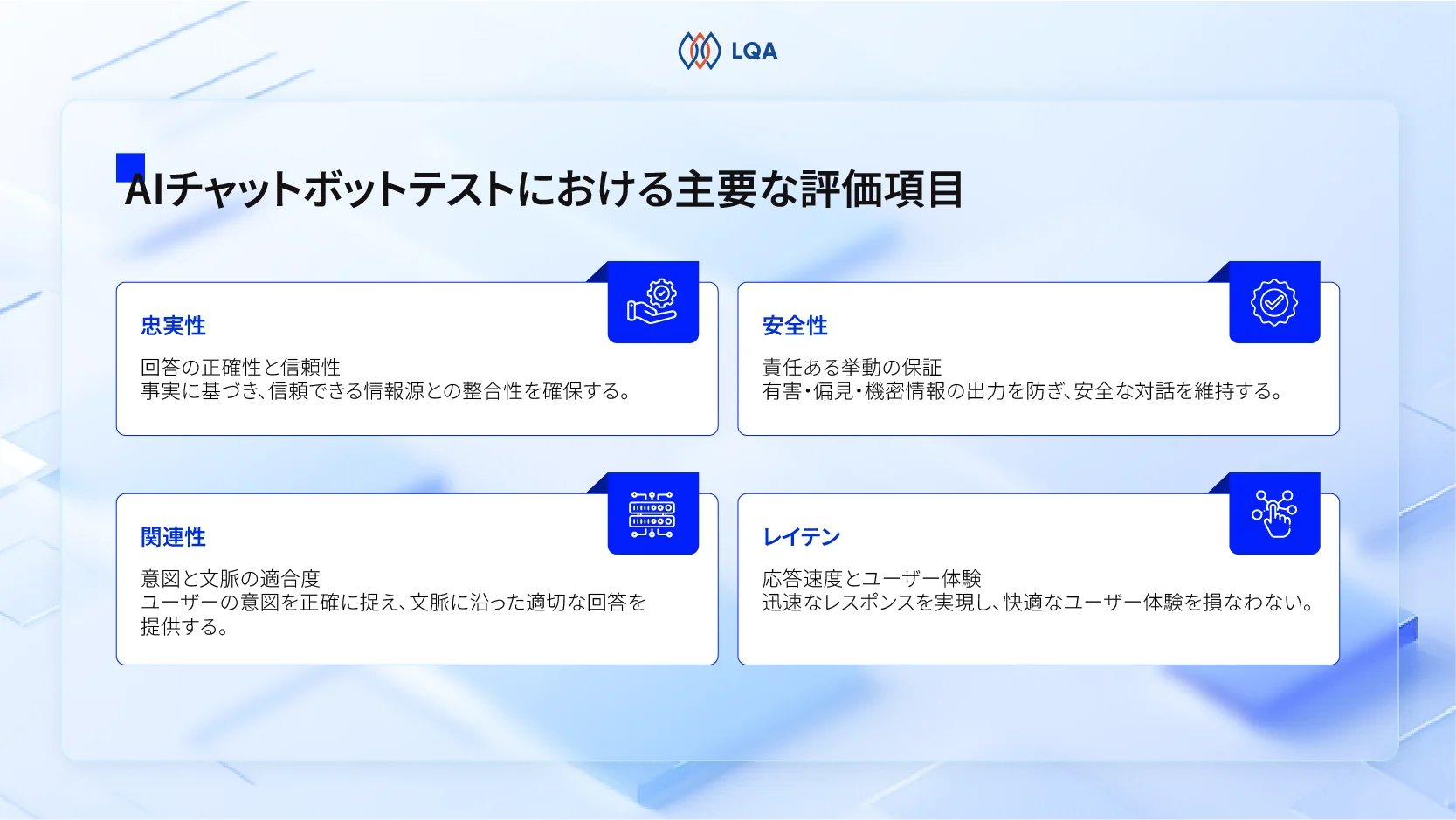
ここまで述べてきた通り、効果的なフィジカルAIシステムを構築するには、高度なアルゴリズムだけでなく、データの品質とシステムの検証精度が鍵となります。認識精度から物理的な実行に至るまで、パイプラインのあらゆる段階で厳密なトレーニングとテストを重ね、動的な環境下で一貫したパフォーマンスを維持しなければなりません。
従来のソフトウェアとは異なり、フィジカルAIは失敗が重大な業務リスクや人身のリスクに直結する現実世界の制約下で動作します。そのため、高品質なトレーニングデータ、正確なアノテーション、そして強固なAIテストフレームワークが成功の必須条件となります。多様で代表的なデータセットで学習させるだけでなく、幅広い現実的なシナリオを通じて継続的にモデルを検証していくことが求められます。
AIソフトウェアがどのように検証されるのか、その実践的なアプローチについては以下のブログもぜひご覧ください。
フィジカルAIのためのAIテスト・データソリューション:LQAの提供価値
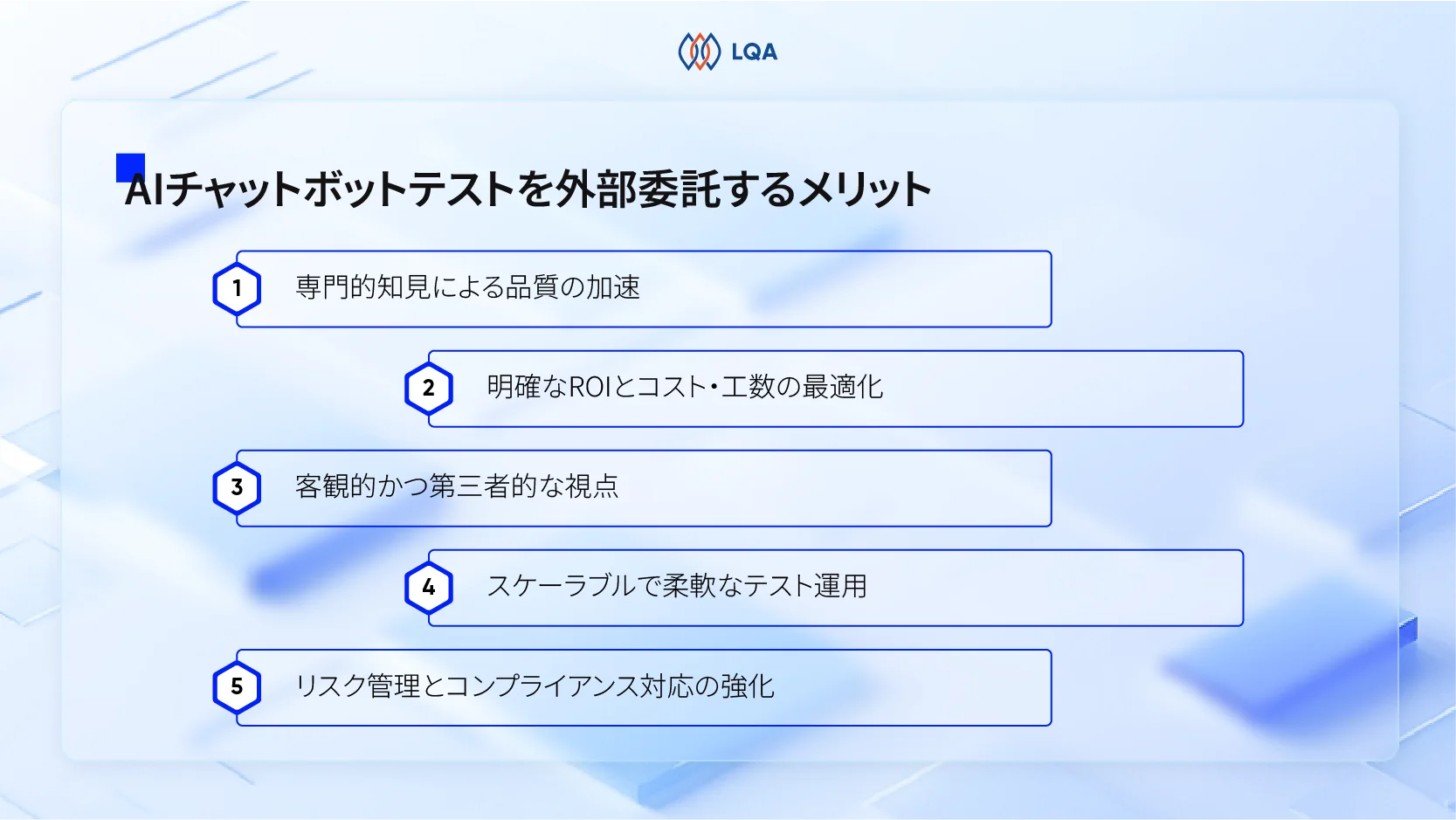
これらの課題に対処するため、LQAはデータ準備からシステム検証に至るまで、AI開発のライフサイクル全体を包括的にサポートするソリューションを提供しています。
AIソフトウェアテストとデータサービスの双方に精通したエキスパートであるLQAは、お客様の以下の取り組みを支援します。
- 正確なデータ収集とアノテーションによる高品質なデータセットの構築
- スケーラブルなデータ処理と検証によるモデル性能の向上
- 高度なAIテスト手法を用いたシステム信頼性の確保
- 複雑かつ動的な環境におけるAI動作の検証
ドメイン知識とAIシステムへの深い理解を掛け合わせ、LQAはお客様がリスクを低減し、導入を加速させ、フィジカルAIソリューションのパフォーマンスを最大化できるよう貢献いたします。
まとめ
フィジカルAIとは、AIの次の大きな進化形であり、その世界の中で物理的に「行動する」ことを可能にする、AIの次なる大きな進化です。製造や物流から医療、モビリティに至るまで、その実用化はすでに産業を変革しており、特に労働力不足などの構造的課題を抱える日本市場では、導入が急速に進んでいます。
しかし、フィジカルAIを大規模に展開するには、データの複雑さや安全性、システムの信頼性といった大きな課題を乗り越える必要があります。成功の鍵は、技術革新そのものだけでなく、データ品質とテスト環境という「強固な基盤」を築くことにあります。
こうした基盤に投資する企業こそが、フィジカルAIの可能性を最大限に引き出し、自動化が進む世界において、効率性、レジリエンス、そして長期的な競争優位性を獲得できるでしょう。
LQAは、高品質なデータと信頼性の高いテストを通じて、お客様のAIモデルのさらなる進化を、開発から現場へのデプロイまで一貫してサポートいたします。フィジカルAIの導入をご検討の際は、ぜひ当社の専門家による無料相談をご利用ください。
- Website: https://lotus-qa.com/jp/
- Tel: (+84) 24-6660-7474
- Mail: [email protected]
- Fanpage: https://www.linkedin.com/company/lts-japan/