Most Up-to-date Data Annotation Trends – Ever heard of it?
Parallel to the fast-paced development of the Artificial Intelligence and Machine Learning market, the field of data annotation is moving forward with the most accelerating trends, both in terms of tools and workflow.
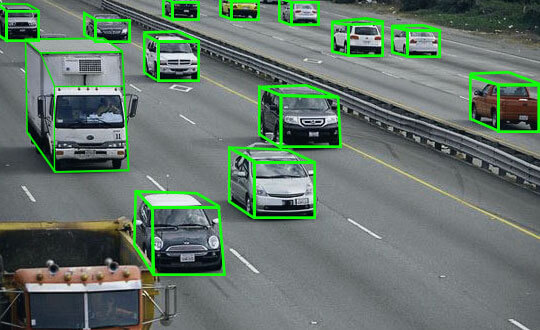
From AI-Powered Virtual Assistant to Autonomous Cars, data annotation has played an important role.
Some might think that data annotation is a boring, timid and time-consuming process, while others might deem it the crucial element of artificial intelligence’s success.
In fact, data annotation, or AI data processing, was once the most-unwanted process of implementing AI in real life. However, with the ever-growing expansion AI in multiple fields of our daily lives, the needs for rich, versatile and high-quality datasets are higher than ever.
In order for a machine to run, in this case, is the AI system, we have to pour training data in so that the “machine” could learn to adapt to whichever is coming at it.
With these trends in the data annotation and AI data processing market, it not only sets a new outlook for the whole market, it also proves the urgent needs for well-annotated datasets.
Predictive Annotation Tools – Auto Labeling Tool
It is pretty obvious that the more fields we can apply Artificial Intelligence and Machine Learning in, the more we need AI data processing.
By saying AI data process, we also mean that we need both the data collection and data annotation.
The rapidly expanding needs of the AI and machine learning market have set a new goal for another focus of the data annotation process. As it is with the Testing market, the demands for auto labeling, or we can call it predictive annotation tools are coming to a peak.

Auto Data Labeling
Basically, the predictive annotation tools (auto labeling tools) are the tools that can automatically detect and label items with the foundation of the similar existing manual annotations.
With the implementation of the aforementioned tools, after some manually annotated data, the toolkit can subsequently annotate the similar datasets.
Throughout this process, the human intervention is limited to the minimum amount, hence saving a lot of time and effort to do such repetitive and boring tasks.
With just some scratches on the surface, auto labeling, or predictive annotation tools may be the pivotal change that will boost up the speed of the annotation process by 80%. But to put one auto labeling tool on the market, it takes years of developing sophisticated features, not to mention a large number of data types need to be put in the data annotation system of that tool. That is why you often see one tool for only one data type.
While the advantages of an auto labeling tool are undeniable, the cost for one commercial tool like that can be enormous.
Emphasis on Quality Control
It is sure that Quality Control plays a huge role in every process. However, the current situation only shows that QC is only circumstantial.
In the future, data engagements at scale will be the main focus, requiring a higher emphasis on quality control.
With more data labeling solutions going into production, and later into the training model of AI systems, more edge cases will be considered.

Emphasis on Quality Control
Under this circumstance, it is a must that you build your own teams of QC to exclusively handle the quality of the annotated datasets. They will not work the way the old QC staff did. On the contrary, these specialized experts can function without detailed guidelines and focus on spotting and fixing issues with large datasets.
What about security? With the security, the QC team should follow a stringent process of maintaining security of the annotation process. This should be ensured throughout the whole project.
Involvement of metadata in data annotation process
From autonomous vehicles to medical imaging, in order for the AI system to run smoothly without glitches, a staggering amount of data is required for annotation.
Metadata is the data clarifying your data. With the same old annotations as the code snippets you put in at the Java class or method level that further define data about the given code without changing any of the actual coded logic, metadata is for data management.

Metadata
All in all, metadata is created and collected for the better utility of that data.
If we can make good use of the metadata, any human errors including misplacing things, management malfunctions, etc. will be tackled. With metadata in hand, we will be able to find, use, preserve and reuse data in a more systematic manner.
- In finding data, metadata speeds up the process of finding the relevant information. Take a dataset in the form of audio for example. Without metadata and the management from it, it would be impossible to us to find the location of the data. This also applies to data types such as images and videos.
- In using the data, metadata gives us a better understanding of how the data is structured, definitions of the terms, its origin (where it was collected, etc.)
- In re-using data, metadata helps annotators navigate the data. In order to reuse data, annotators are to have careful reservation and documentation of the metadata.
The key to making all of this happen is data annotation. Adding metadata to datasets helps detect patterns and annotation helps models recognize objects.
With all the benefits of metadata in how we can manage and use the datasets, many firms now have grown interested in developing metadata for better management.
Workforce of SMEs
The rapidly growing number of the industries embracing AI, a subject-specific data annotation team is of urgent needs.
For every domain such as healthcare, finance, automotive, etc. a team trained with custom curricular will be deployed on projects, hence expert annotators built over time. With this being done, more value and high-quality to the annotation process will be focused with a deeper approach, and this strategy will start with the validation of guidelines to time of data delivery.
Do you want to deploy these data annotation trends? Come and contact LQA for further details:
- Website: https://www.lotus-qa.com/
- Tel: (+84) 24-6660-7474
- Fanpage: https://www.facebook.com/LotusQualityAssurance