インテリジェントバーチャルアシスタント(IVA):音声アノテーション による巨大な市場規模
インテリジェントバーチャルアシスタント(IVA)市場規模は、2020年には約40億米ドルの規模に達しました。そして、この市場は、2022年に177.2億米ドルの市場価値から、2030年までに1,760.5億米ドルに達すると推定され、予測期間中に38.82%のCAGRで成長すると予想されています。
AIによるバーチャルアシスタントの可能性と有用性は、技術的な側面と行動的な側面の両方からもたらされます。アプリ上でのアシスタントに対する需要の高まりと相関して、データトレーニングのためにAIシステムに継続的に入力されるデータがあります。 逆に言えば、AIを搭載したバーチャルアシスタントを実現するために最も重要な機能の一つが、データ入力、つまり音声アノテーションです。
1. インテリジェントバーチャルアシスタント(IVA)の急成長する業界
まず、IVA(Intelligent Virtual Assistant)とは、AIを搭載した仮想アシスタントというもので、人間と同じような応答ができるように開発されたソフトウェアのことです。 このアシスタントにより、質問をしたり、手配をしたり、さらには実際の人間のサポートを要求することができます。
1.1. なぜが台頭してきたのか?
IVAは、主に顧客対応のコスト削減のために広く利用されています。また、ライブチャットやその他の形式のカスタマーエンゲージメントに迅速に対応することで、IVAは顧客サービスの満足度を高め、時間を節約するのに役立ちます。
IVAは、上記のような外部パフォーマンスに加えて、顧客情報を収集し、会話や顧客満足度調査の回答を分析することで、組織が顧客と企業のコミュニケーションを改善するのに役立てています。

バーチャルアシスタントと 音声アノテーション
インテリジェントなバーチャルアシスタントは、企業のアバターのような役割を果たします。顧客からの問い合わせを動的に読み取り、理解し、対応することができ、最終的には様々な部門のマンパワーのコストを削減することができます。
このようなIVAは、インフラのセットアップコストを省くことができるため、大企業に多く導入されています。これが、近年のIVAの収益が非常に高い理由であり、今後もそうなる可能性があります。
1.2.IVAは何ができるのか?
AIを活用した仮想支援の使い安さや導入状況はいたるところで見られます。オペレーティングシステムやモバイルアプリケーション、あるいはチャットボットでも目にすることができます。機械学習やディープニューラルネットワークなど、AI技術の進歩を展開することで、仮想アシスタントはいくつかの特定のタスクを簡単にこなすことができます。
バーチャルアシスタントは、オペレーティングシステムでは非常に一般的です。これらのアシスタントは、カレンダーの設定、手配、アラームの設定、質問、さらにはテキストの作成などをサポートします。このようなマルチタスクのアシスタントは大規模なものであり、このようなアプリケーションはオペレーティングシステムの中だけに限られると思われるかもしれません。
しかし、モバイルユーザーやモバイルアプリの数が急増していることから、多くの起業家やスタートアップ企業が、自社製品のアプリ内にバーチャルアシスタントを導入し始めています。これにより、さまざまな分野で必要とされるデータ入力の需要が高まっています。
例えば、ヘルスケアサービスのアプリでは、医学用語などヘルスケアに関連する特定の 音声アノテーション が必要です。
ResearchAndMarkets.comの「インテリジェントバーチャルアシスタント(IVA)の世界市場2019-2025年」に関するレポートによると、「Industry Size, Share & Trends」と題して、次のように指摘しています。スマートスピーカーは最も速いペースで発展しており、IVAの主要ドメインとして浮上している。IVAでは、Text to Speechが最大のセグメントです。2025年には153億7,000万ドル以上の売上に達すると予測されています。
IVAの市場で優位に立っている国はヘルスケアを主要産業とする北米です。主要なプレイヤーは、Apple Inc.、Oracle Corporation、CSS Corporation、WellTok Inc.、CodeBaby Corporation、eGain Corporation、MedRespond、Microsoft、Next IT Corporation、Nuance Communications, Inc.、True Image Interactive Inc.などです。
このレポートを通して、AI搭載のバーチャルアシスタント市場の発展と成長の可能性が急成長していることがわかります。異なるドメインごとに、IVA導入のための異なるアプローチがあります。
より良いサービスやビジネスの発展のために、企業は効果的なカスタマーエンゲージメントを求めており、そのため、様々な製品に実装される仮想アシスタントの数は増加しています。
現在、インテリジェントバーチャルアシスタント市場は、導入率の高さとIT投資の増加を背景に、主にBFSI産業の垂直軸によって牽引されています。しかし、自動車およびヘルスケア分野は最も収益性の高い垂直セグメントであり、予測期間中もこの傾向を維持すると思われます。
2. 音声アノテーション はIVAにどのように役立つのか?
通話、ショッピング、音楽配信、コンサルティングなど、生活のあらゆる場面でバーチャルアシスタントが登場するようになり、音声データ処理の必要性が高まっています。また、Speech to TextやText to Speechによるアノテーションだけでなく、より高度な形式であるPart of スピーチタギングや音声学によるアノテーションも求められています。
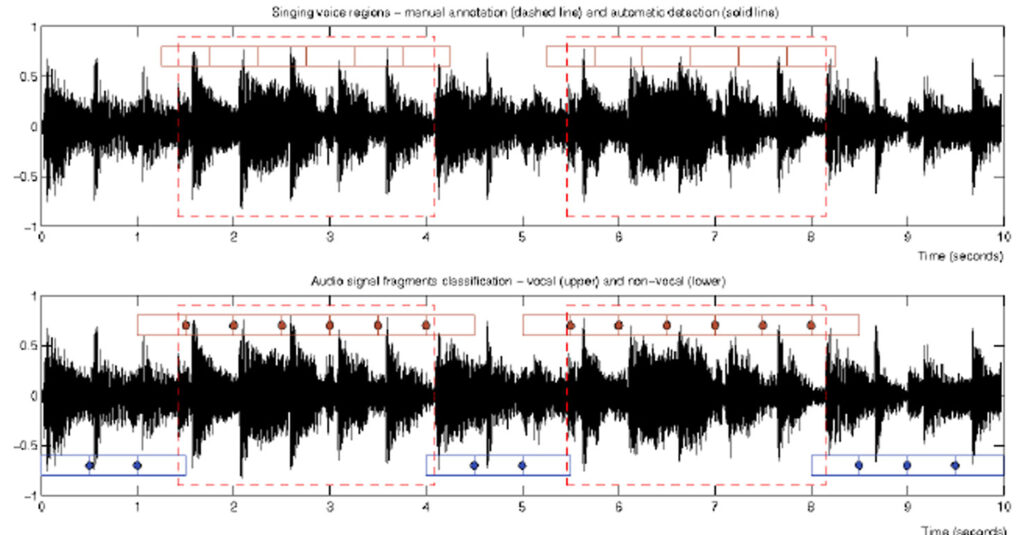
バーチャルアシスタントのための 音声アノテーション
IVAシステムが適切に動作するためには、開発者は以下のような様々なアプローチの対話方法を考慮しなければなりません。
Text-to-text::テキスト・ツー・テキストのアノテーションは、必ずしもIVAの動作に直接関係しません。しかし、ラベル付けされたテキストは、機械が人間の自然言語を理解するのに役立ちます。適切に行われなければ、アノテーションされたテキストは、機械に文法的なエラーを起こさせたり、顧客からの問い合わせを誤って理解させたりする可能性があります。
Speech-to-text: スピーチ・ツー・テキスト アノテーションは、音声ファイルをテキストに書き起こし、通常はワープロで編集や検索ができるようにするものです。Siri、Alexa、Google Assistantなどの音声認識アシスタントがその代表例です。
Text-to-speech: テキスト・トゥ・スピーチ アノテーションでは、幅広い声質(男性、女性)とアクセント(北部、中部、南部アクセント)の自然な音声を合成することができます。
Speech-to-Speech: スピーチ・ツー・スピーチ(音声合成)は、最も高度で複雑なアノテーションです。これにデータを入力することで、AIはユーザーの音声を理解し、それに応じた回答やパフォーマンスを行うことができます。
いずれにしても、データ、声、スピーチ、会話などを収集し、機械学習アルゴリズムがユーザーからの入力を理解できるようにアノテーションする必要があります。
音声 アノテーションサービス では、理解しやすく有用なデータセットを提供するために多くの努力が必要です。また、アノテーターの採用やトレーニングにも多くの時間を要し、作業時間は言うまでもありません。
- Website: https://jp.lotus-qa.com/
- Tel: (+84) 24-6660-7474
- Fanpage: https://www.facebook.com/LotusQualityAssurance