ホワイトボックステストは、ソフトウェア開発における必須の手法の一つです。ブラックボックステストと並んで、ソフトウェアの品質を確保するための貴重な手段として広く活用されています。この手法は、効率的でかつ費用対効果の高いテスト手法として業界で高い評価を受けています。
この記事では、ホワイトボックステストの優れたメリットや様々な種類、さらにその効果的な活用方法について、詳細に解説していきます。ソフトウェアの内部構造を深く理解し、コードの品質を向上させるための戦略的な手法として、ホワイトボックステストの価値を探求していきましょう。
ホワイトボックステストの基礎知識
本記事の最初章で、ホワイトボックステストの基本的な定義、ブラックボックステストの違う点及びホワイトボックステストの対象について説明していきます。
ホワイトボックステストとは
ホワイトボックステストは、ソフトウェアのテスト手法の一つであり、システムの内部構造や論理的な仕組みに焦点を当てた手法です。プログラムの外部仕様やユーザーの視点からではなく、コードやアルゴリズムの内部でどのように動作するかを重点的に検証します。
ホワイトボックステストの特徴
ホワイトボックステストでは、プログラムの内部で使用されている命令や分岐などが正しく動作しているかをチェックします。テスターは、ステートメントカバレッジ、ブランチカバレッジ、パスカバレッジな、さまざまなテクニックを活用して、ソフトウェアのコードベースを細部まで検査どします。この入念なアプローチにより、コードの各行が検証され、未検出のエラーやバグのリスクが最小限に抑えられます。
ホワイトボックステストはソフトウェアの内部構造と設計に対する貴重な洞察も提供します。テスターは、異なるコードコンポーネントがどのように相互作用し、データがシステムを流れるかについて、より深い理解を得ます。この向上した理解により、SDLCの早い段階で潜在的な問題や設計上の欠陥を特定し、長期的には時間とリソースを節約することが可能となります。
該当レベル
ソフトウェアを検証する際には、異なるソフトウェアテストの種類とテストレベルが存在します。ホワイトボックステストは、ソフトウェアテストにおける次のレベルにも適用できます。
単体テスト
単体テストは、ホワイトボックステスト技術の適用に最適な環境を提供します。このレベルでは、個々のコンポーネントを個別に検査し、プログラムを構成する比較的小さな単位(ユニット)が正確にその指定された機能を果たしていることを確認します。
ホワイトボックステストは、テスターがコードベースに深く入り込み、コードパスを入念に検証し、エッジケースを処理し、全体的な堅牢性を確保します。単体テスト中にホワイトボックステスト技術を活用することで、各コンポーネントの内部ロジックが徹底的に検証されます。これにより、潜在的な欠陥やエラーを特定し、コードを改善して信頼性とパフォーマンスを向上させることができます。
統合テスト
システム開発におけるプログラムの検証作業の中でも、手続きや関数といった個々の機能を結合させて、うまく連携・動作しているかを確認するテスト。ホワイトボックステストは、個々の機能が統合された際の相互作用やデータフローを詳細に分析し、システム全体の品質を確保するのに役立ちます。
システムテスト
システムやソフトウェアを構築した後に実行するテスト。ホワイトボックステストは、システムテストの一環として、ソフトウェア品質を検証します。内部の論理構造やコードの動作を理解することで、システム全体の問題やエラーを早期に発見し、修正することができます。
ホワイトボックステストは主に単体テストと関連しているかもしれません。ただし、統合テストやシステムテストの段階全体に適用することで、ソフトウェアの内部構造をより深く理解し、開発の各レベルで包括的なテストカバレッジを確保し、テストプロセス全体を強化することができます。
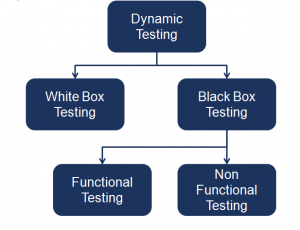
ホワイトボックステストとブラックボックステストの違い
ホワイトボックステストとブラックボックステストは、ソフトウェアテストにおける二つの基本的な方法論であり、それぞれが異なるアプローチと目的を持っています。
ブラックボックステストは、システムの外部仕様に基づいてテストを行う手法です。テスターは、システムが外部からどのように見えるかを重視し、内部の詳細には関心を持ちません。この手法では、システムの入力と出力を操作し、その振る舞いを観察して検証します。テストケースは、システムが正しく機能し、要件を満たしているかどうかを確認するために設計されます。ブラックボックステストは、システムの機能性やユーザビリティ、パフォーマンスなど、外部の視点からのテストを強調しています。
一方、ホワイトボックステストは、システムの内部構造やロジックに焦点を当ててテストを行います。この手法では、テスターはシステムのソースコードや内部の実装にアクセスし、コードのパスやデータフローを詳細に分析します。テストケースは、プログラムの各機能や分岐条件が正しく動作しているかどうかを確認するために設計されます。ホワイトボックステストは、プログラムの内部品質や構造の正確性を確認することに焦点を当てており、ソフトウェアのロジックエラーや隠れたバグを特定するのに役立ちます。

ブラックボックステストとホワイトボックステストは、ソフトウェア品質保証において重要な役割を果たします。これらのテスト手法の選択は、テストの目的、プロジェクトの段階、そして利用可能なリソースなど、様々な要素に依存します。
もし、ホワイトボックステストの導入に悩んでいるか、プロジェクトに最適なアプローチを見極めるのに迷っている場合は、LQAにお任せください。LQAは、ソフトウェアテストを専門とするベトナムの先駆的企業であり、約10年の豊富な経験と専門知識を持っています。プロジェクトの要件や特性を徹底的に分析し、お客様の予算や目標にシームレスに適合するテストアプローチを提案します。

ホワイトボックステストのメリットとデメリット
ホワイトボックステストは下記のようなメリットとデメリットをもたらします。

メリット
徹底性
ホワイトボックステストはソフトウェア内のすべてのコードパスを網羅する徹底性が特徴です。このテスト手法の目的は、通常、可能な限り多くのコードをテストすることです。この包括的なアプローチにより、すべてのコードが厳密に検証され、隠れているかもしれない欠陥を検出する可能性が高まり、テストカバレッジが向上します。
自動化の可能性
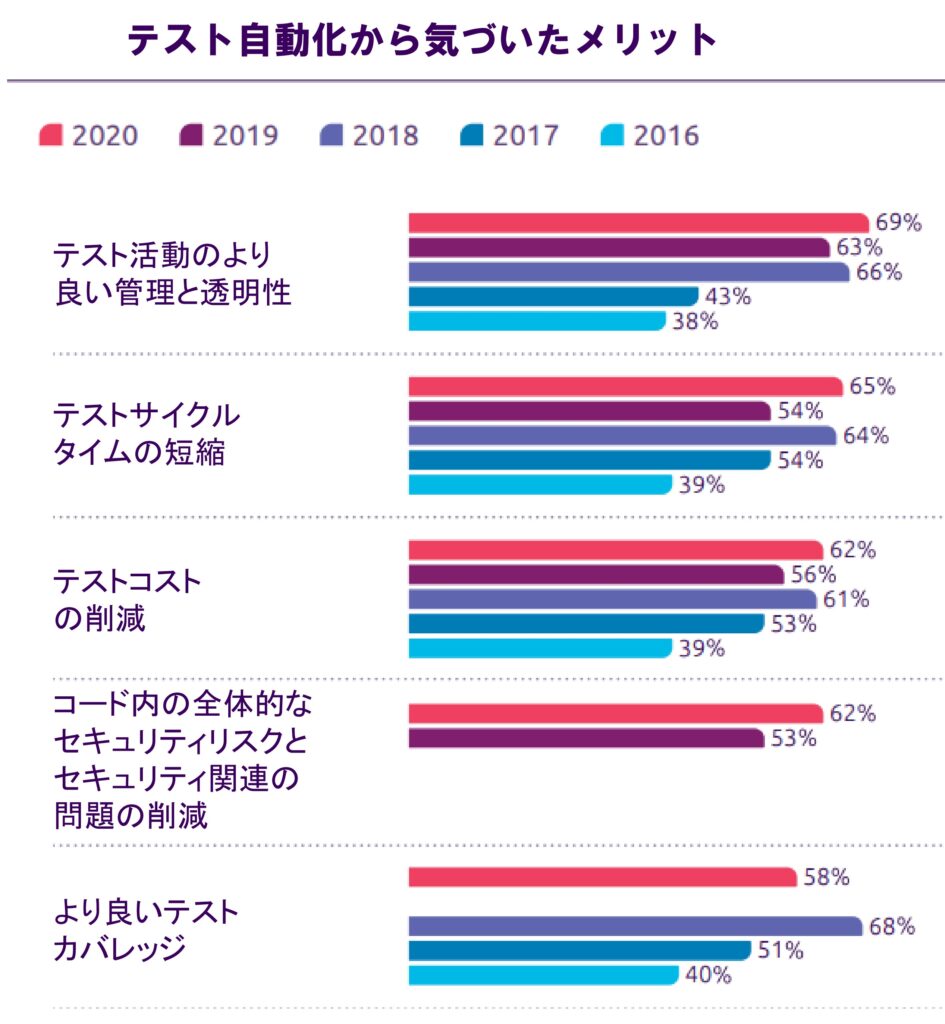
ホワイトボックステストは自動化に非常に適しており、効率的かつコスト効果の高いテストソリューションとなっています。テストスクリプトはコードベースと直接やり取りできるため、繰り返しのテストやリグレッションテストを容易に実行できます。自動化テストツールを使用して、テストケースを実行したり、コードカバレッジを分析したり、包括的なレポートを生成したりすることができます。これにより、企業はテストプロセスを効率化し、貴重な時間とリソースを節約することができます。
また、自動化により、繰り返しのタスクを迅速かつ正確に実行できるため、テスターはソフトウェアのより複雑で重要な側面に集中することができます。
自動テストに関する詳細は、当社の「自動テストとは?メリット・デメリットや導入ステップを解説」の記事をご覧ください。
長期的な戦略的なコスト削減をお考えでしたら、ぜひ当社の専門家とお話ししてください。LQAは高品質な自動化テストサービスを提供し、熟練したテスターを活用して、クライアントの期待に応える成果をもたらします。
深い理解
ホワイトボックステストは、ソフトウェアの内部構造を詳細に調査することで、開発者が各コンポーネントやモジュールがどのように機能し、相互作用するかを理解するのに役立ちます。この深い理解により、開発者はソフトウェアの構造に関する洞察を得て、特定のコードの複雑さや重要なエリアを特定することが可能となります。
開発者は、ソフトウェアの内部構造やロジックに対する深い理解を活かして、より効果的なテスト戦略を策定することができます。このようにして、開発者はユーザーにとってより安定したおよび高品質なソフトウェア製品を提供することができます。
コードの最適化
ホワイトボックステストは、コードの実行パスに対する洞察を提供するため、効率的なソフトウェアの構築に貢献します。
このテスト手法によって、不必要なコードや冗長な処理が発見されることで、プログラムの最適化が可能となります。不要なコードや冗長な処理を特定することで、ソフトウェアのパフォーマンスが向上し、リソースの効率的な利用が促進されます。さらに、コードの最適化によって、ソフトウェアのメンテナンスや拡張性も向上し、将来的な開発作業がスムーズに進むことが期待されます。
デメリット
一方、ホワイトボックステストにはいくつかのデメリットも存在します。
複雑さとスキル要件
ホワイトボックステストの実施は、システムの内部構造に焦点を当てるため、テスターがプログラミング言語やソフトウェアアーキテクチャに深い理解を持っていることが不可欠です。
また、複雑なアプリケーションや大規模なソフトウェアシステムの場合、テストケースの設計や実行には緻密な計画と高度な技術が必要です。テストケースのカバレッジを確保し、適切なテストデータを作成し、テストの実行と結果の分析を行うためには、テスターが高度なテストスキルや問題解決能力を持っていることが求められます。
コスト・時間のかかり
ホワイトボックステストのデメリットの一つは、その実施にかかるコストと時間の増加です。徹底的なテストが行われるため、ブラックボックステストと比較して、ホワイトボックステストはより高いコストがかかる場合があります。ホワイトボックステストでは、各機能やコンポーネントが正しく動作するかどうかを確認するために、大量のテストコードを書くことが必要です。これも技術チームの手間を大幅に取れます。
そのため、プロジェクトの予算やスケジュールに制約がある場合、ホワイトボックステストの実施には注意が必要です。
ホワイトボックステストを適切に導入すれば、コードの品質向上や時間の節約、製品の改善など、多くの利点を享受できます。しかしながら、この種のテストを利用する際には避けられない課題も存在します。そのため、ホワイトボックステストを効果的に実施したい方は、LQAのような専門的なソフトウェアテスト会社にご相談ください。
LQAは豊富な経験と幅広いスキルを持つIT専門家を擁し、革新的な自動テストソリューションを提供しています。さらに、日本とベトナムの人件費の差を活かして、お客様の期待に応えるチームを素早く構築し、コストを最大30%削減することが可能です。
ホワイトボックステストの網羅基準
ホワイトボックステストにおける網羅基準は、テストがソフトウェアのあらゆる側面を包括的にカバーすることを確保するための基準です。これらの基準により、開発者やテスターはソフトウェアの品質や信頼性を確実に向上させることができます。下記はホワイトボックステストにおける代表的なコードカバレッジです。
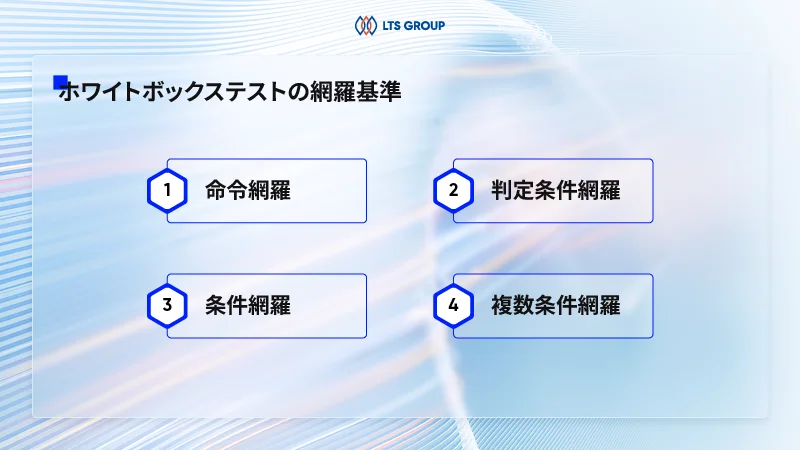
命令網羅
命令網羅(ステートメントカバレッジ)は、テストがプログラム内のすべての命令を少なくとも一度は実行することを確認する基準です。つまり、プログラム内のすべての命令がテストケースに含まれることを目指します。これにより、コード内の個々の命令が正しく実行されるかどうかを確認し、カバレッジ率を向上させます。
判定条件網羅
判定条件網羅はプログラム内のすべての条件文の真偽値が少なくとも一度は評価されることを確認する基準です。つまり、条件文が真と偽の両方の結果になることを確認します。これにより、条件分岐におけるすべての可能なパスがテストされ、コードの正確性が確認されます。
条件網羅(ブランチカバレッジ)
条件網羅は、ソフトウェア内の全ての条件式の組み合わせが少なくとも一度は実行されるように、テストケースを設計することを指します。この基準では、ソースコード内の各条件分岐の真偽が、テストでどの程度出現したかを評価します。これによって、プログラムのあらゆる条件式が適切に検証され、動作が正確であることを確認します。
複数条件網羅
最後に、複数条件網羅も重要な基準の一つです。この基準では、複数の条件式が組み合わさった状態でのテストケースを設計することが求められます。これにより、複雑な条件式や条件の組み合わせが適切に処理され、プログラムの動作が完全に理解されます。
基本的なホワイトボックステストの手法
ホワイトボックステストにはさまざまな手法がありますが、その中でも基本的な手法には、ベースラインテスト、制御フローテスト、およびデータフローテストがあります。
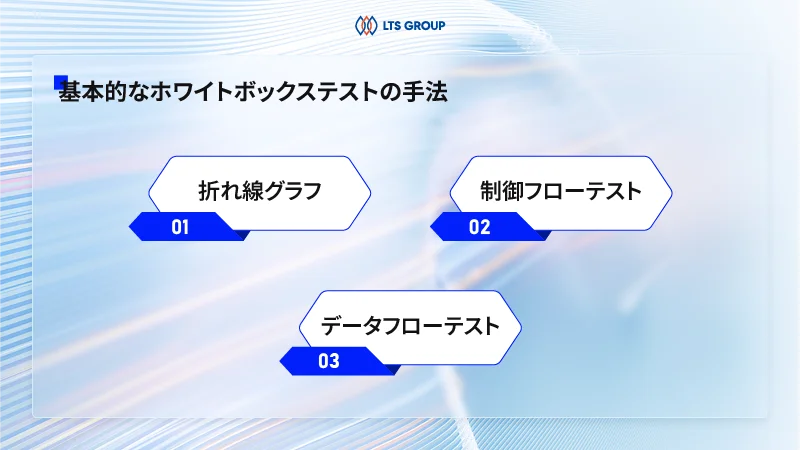
ベースライン テスト/折れ線グラフ
ホワイトボックステストにおけるベースラインテスト、または折れ線グラフ法は、Tom McCabeによって初めて導入されました。この手法は、プログラムの制御フローグラフに類似しており、アルゴリズムの記述やコンポーネントの関係を視覚的に示すのに役立ちます。
ベースラインテスト/折れ線グラフは、アルゴリズムの実装に関する情報を提供し、テストケースの設計者が手続きの複雑さを理解するのに役立ちます。この手法は、ノードとアークという2種類のコンポーネントで構成されています。
折れ線グラフには様々なタイプのボタンがあります。たとえば、制御フローグラフにはバイナリ決定ノードのみが含まれている場合、それをバイナリ制御フローグラフと呼びます。
ベースラインテスト/折れ線グラフは、プログラムの内部構造を理解し、テストケースの設計や分析を行う際に重要なツールとなります。これにより、開発者やテスターはプログラムの振る舞いを視覚化し、検証することができます。
制御フローテスト
制御フローテスト方法はソフトウェアユニットのすべての実行パスが適切に実行されることを確認するために使用されます。実行パスとは、特定のソフトウェアユニットのエントリポイントから終了ポイントまでの、実行されるコマンドの順序付きリストです。ソフトウェアコンポーネントごとに異なる実装パスがありますが、制御フローテストの目的は、テスト中のすべての実行パスを網羅し、適切に実行されることを確認することです。
例えば、以下のコードを考えてみましょう。
for (i=1; i<=1000; i++)
for (j=1; j<=1000; j++)
for (k=1; k<=1000; k++)
doSomethingWith(i,j,k);
このコードには1つの実行パスがありますが、非常に長い実行パスです。制御フローテスト方法を使用して、このコードのすべてのループが正しく動作し、期待どおりの結果が得られることを確認することが重要です。
データフローテスト
データフローテストはプログラムのデータの流れの整合性と正確性を評価する方法です。制御フローテストとは異なり、プログラムステートメントの実行順序に焦点を当てる制御フローテストとは異なり、データフローテストはデータがプログラムを通じてどのように移動するかを詳細に検討します。これは、データの操作、保存、取得に関連する潜在的な脆弱性、エラー、または異常を特定することを目的としています。
データフローテストはソフトウェアの内部構造とロジックを調査する白箱テストで重要な役割を果たします。データフローパスに深く入り込むことで、白箱テスターは他のテスト方法では明らかにならない隠れた欠陥、セキュリティの脆弱性、および論理エラーを発見することができます。
プロジェクトの要件に応じて、最適なテスト手法を選択することが重要です。LQAの経験豊富で専門知識に裏打ちされたテスターは、プロジェクトにおいて最適な戦略を策定し、ホワイトボックステストを効果的に実施できます。これまでに、教育、金融、建設、ヘルスケア、自動車などの業界におけるお客様にテストサービスを提供し、国際標準を満たす優れた成果を収めてきました。これにより、顧客満足度は94%に達し、高い信頼を得てきました。
ホワイトボックステストの基本的な手順
以下は、ホワイトボックステストを実施するための基本的な手順です。
テストを実施するための準備
ホワイトボックステストプロセスを開始する前に、ソフトウェアの要件、仕様、および設計を理解することが極めて重要です。テスターは、テスト対象のソフトウェアのソースコード、アーキテクチャ、および実装の詳細に精通する必要があります。さらに、テストが必要な機能、モジュール、またはコンポーネントを特定する必要があります。この理解は、テスターが効果的なテストケースを作成し、コードの包括的なカバレッジを確保するのに役立ちます。
また、テスト計画もホワイトボックステストにおける重要な段階です。テスターはテストの目的、範囲、アプローチ、および必要なリソースを明確にするテスト計画を策定します。この計画には、テストシナリオ、テストケース、およびテストデータの定義も含まれるべきです。徹底的な計画により、テスト活動がプロジェクトの目標と一致することが確実になります。
テストの作成と実行
準備段階が完了したら、テスターは特定された要件と仕様に基づいてテストケースを作成します。テストケースはソフトウェアの内部ロジックやコードパスの正確性や堅牢性を検証するために設計されます。テスターはステートメントカバレッジ、ブランチカバレッジ、パスカバレッジ、およびデータフローカバレッジなどの様々なホワイトボックステスト手法を活用して包括的なテストカバレッジを確保します。
テストケースの作成手法の詳細については当社の「例を含む5つのテストケースの作成手法のガイド」の記事をご覧ください。
テストケースの作成中、テスターはソフトウェア内の異なるコードパス、条件、および決定ポイントに焦点を当てます。特定のコードセグメント、ループ、ブランチ、および例外処理メカニズムを実行するためのテストケースを設計します。テスト入力は、有効および無効なシナリオ、境界条件、およびエッジケースをカバーするように慎重に選択されます。
テストケースが作成されたら、テスターはそれらをテスト対象のソフトウェアに対して実行します。自動テストツールを使用してテストの実行プロセスを効率化することができます。テスト結果が記録され、テスト中に発生した任意の逸脱や失敗が記録されます。
テストレポートの作成
テスト実行段階が完了した後、テスターはテスト結果をまとめ、包括的なテストレポートを作成します。これらのレポートには、ソフトウェアの挙動、テスト中に発生した欠陥や問題、および達成された全体的なテストカバレッジが含まれます。
テストレポートには通常、実行されたテストケースの数、合格/不合格のステータス、コードカバレッジメトリクス、欠陥ログ、および改善のための推奨事項が含まれます。テスターはテスト結果を分析し、ソフトウェアに潜む問題や傾向を特定し、今後の改善の方向性を見出すことができます。
LQAは、ヘルスケア、自動車、教育などの業界に特化したカスタマイズされたテストサービスを提供しています。私たちの専門家は、これらの業界におけるシステムの内部構造に深く理解を持ち、その知識を活用してホワイトボックステストの手順を最適化し、効果的なテストケースを設計し、実行することができます。
また、LQAの強みは日本語と英語の相互スキルにあります。これらの言語を使いこなすことで、開発段階での円滑なコミュニケーションが実現されます。その結果、予期せぬトラブルにも迅速に対応でき、プロジェクトの被害やリスクを最小限に抑えることができます。
よくある質問
ホワイトボックステストとは?
ホワイトボックステストは、ソフトウェアの内部構造やコードの動作を詳細に検証するテスト手法です。開発者やテスターがソフトウェアのコードやアルゴリズムにアクセスし、その内部の仕組みを理解してテストケースを設計し、検証します。これにより、ソフトウェアの品質や信頼性を向上させることができます。
ホワイトボックステストにはどんな種類がありますか?
ホワイトボックステストには、制御フローテスト、データフローテストなどの主要な種類があります。
ホワイトボックステストのメリットは?
ホワイトボックステストは徹底性やシステムに関する深い理解、コードの最適化など、多くのメリットをもたらします。これらのメリットにより、ホワイトボックステストは隠れたバグを早期に検出し、製品の品質とパフォーマンスを向上させるための深い洞察を提供します。
結論
まとめると、ホワイトボックステストは、ソフトウェアシステムの内部構造やロジックを深く掘り下げることで、その完全性と信頼性を確保する上で重要な役割を果たします。このテスト手法は、その複雑さから課題も伴いますが、LQAのような経験豊富なテスト企業との提携により、これらの障壁を克服することができます。
LQAの専門知識とカスタマイズされたテストサービスを通じて、日本企業は徹底的なホワイトボックステストを実施し、潜在的な問題を特定し、全体的なソフトウェア品質を向上させることができます。ホワイトボックステストをLQAに任せることで、組織はソフトウェアの検証の複雑さを自信を持って乗り越え、顧客に優れた製品を提供すると同時に、他の主要な目標やビジネスに集中することができます。