
In this dynamic era of machine learning, the fuel that powers accurate algorithms and AI breakthroughs is high-quality data. To help you demystify the crucial role of data annotation for machine learning, and master the complete process of data annotation from its foundational principles to advanced techniques, we’ve created this comprehensive guide. Let’s dive in and enhance your machine-learning journey.
Data Annotation for Machine Learning
What is Machine Learning?
Machine learning is embedded in AI and allows machines to perform specific tasks through training. With data AI annotation, it can learn about pretty much everything. Machine learning techniques can be described into four types: Unsupervised learning, Semi-Supervised Learning, Supervised Learning, and Reinforcement learning
- Supervised Learning: Supervised learning learns from a set of labeled data. It is an algorithm that predicts the outcome of new data based on previously known labeled data.
- Unsupervised Learning: In unsupervised machine learning, training is based on unlabeled data. In this algorithm, you don’t know the outcome or the label of the input data.
- Semi-Supervised Learning: The AI will learn from a dataset that is partly labeled. This is the combination of the two types above.
- Reinforcement Learning: Reinforcement learning is the algorithm that helps a system determine its behavior to maximize its benefits. Currently, it is mainly applied to Game Theory, where algorithms need to determine the next move to achieve the highest score.
Although there are four types of techniques, the most frequently used are unsupervised and supervised learning. You can see how unsupervised and supervised learning works according to Booz Allen Hamilton’s description in this picture:
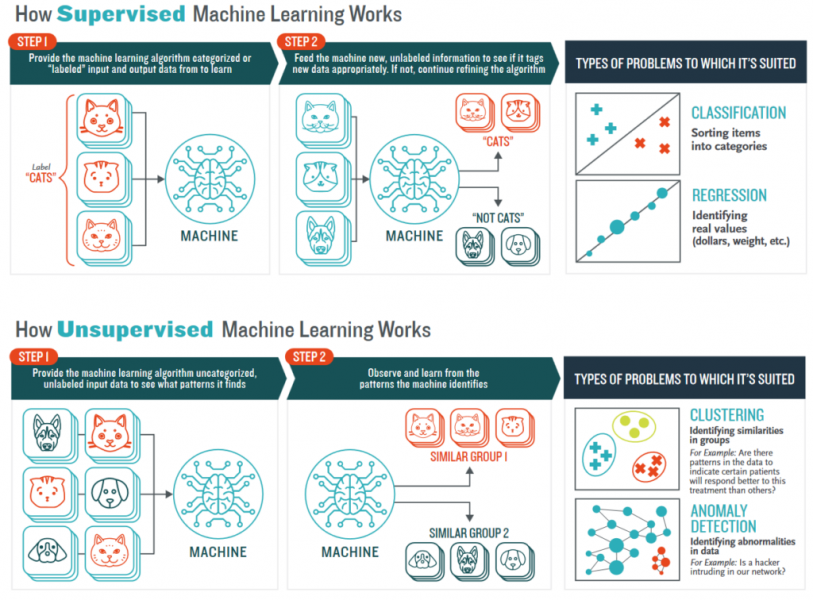
How data annotation for machine learning works
What is Annotated Data?
Data annotation for machine learning is the process of labeling or tagging data to make it understandable and usable for machine learning algorithms. This involves adding metadata, such as categories, tags, or attributes, to raw data, making it easier for algorithms to recognize patterns and learn from the data.
In fact, data annotation, or AI data processing, was once the most unwanted process of implementing AI in real life. Data annotation AI is a crucial step in creating supervised machine-learning models where the algorithm learns from labeled examples to make predictions or classifications.
The Importance of Data Annotation Machine Learning
Data annotation plays a pivotal role in machine learning for several reasons:
- Training Supervised Models: Most machine learning algorithms, especially supervised learning models, require labeled data to learn patterns and make predictions. Without accurate annotations, models cannot generalize well to new, unseen data.
- Quality and Performance: The quality of annotations directly impacts the quality and performance of machine learning models. Inaccurate or inconsistent annotations can lead to incorrect predictions and reduced model effectiveness.
- Algorithm Learning: Data annotation provides the algorithm with labeled examples, helping it understand the relationships between input data and the desired output. This enables the algorithm to learn and generalize from these examples.
- Feature Extraction: Annotations can also involve marking specific features within the data, aiding the algorithm in understanding relevant patterns and relationships.
- Benchmarking and Evaluation: Labeled datasets allow for benchmarking and evaluating the performance of different algorithms or models on standardized tasks.
- Domain Adaptation: Annotations can help adapt models to specific domains or tasks by providing tailored labeled data.
- Research and Development: In research and experimental settings, annotated data serves as a foundation for exploring new algorithms, techniques, and ideas.
- Industry Applications: Data annotation is essential in various industries, including healthcare (medical image analysis), autonomous vehicles (object detection), finance (fraud detection), and more.
Overall, data annotation is a critical step in the machine-learning pipeline that facilitates the creation of accurate, effective, and reliable models capable of performing a wide range of tasks across different domains.

Best data annotation for machine learning company
How to Process Data Annotation for Machine Learning?
Step 1: Data Collection
Data collection is the process of gathering and measuring information from countless different sources. To use the data we collect to develop practical artificial intelligence (AI) and machine learning solutions, it must be collected and stored in a way that makes sense for the business problem at hand.
There are several ways to find data. In classification algorithm cases, it is possible to rely on class names to form keywords and to use crawling data from the Internet to find images. Or you can find photos, and videos from social networking sites, satellite images on Google, free collected data from public cameras or cars (Waymo, Tesla), and even you can buy data from third parties (notice the accuracy of data). Some of the standard datasets can be found on free websites like Common Objects in Context (COCO), ImageNet, and Google’s Open Images.
Some common data types are Image, Video, Text, Audio, and 3D sensor data.
- Image data annotation for machine learning (photographs of people, objects, animals, etc.)
Image is perhaps the most common data type in the field of data annotation for machine learning. Since it deals with the most basic type of data there is, it plays an important part in a wide range of applications, namely robotic visions, facial recognition, or any kind of application that has to interpret images.
From the raw datasets provided from multiple sources, it is vital for these to be tagged with metadata that contains identifiers, captions, or keywords.
The significant fields that require enormous effort for data annotation for machine learning are healthcare applications (as in our case study of blood-cell annotation), and autonomous vehicles (as in our case study of traffic lights and sign annotation). With the effective and accurate annotation of images, AI applications can work flawlessly with no intervention from humans.
To train these solutions, metadata must be assigned to the images in the form of identifiers, captions, or keywords. From computer vision systems used by self-driving vehicles and machines that pick and sort produce to healthcare software applications that auto-identify medical conditions, there are many use cases that require high volumes of annotated images. Image annotation increases precision and accuracy by effectively training these systems.

Image data annotation for machine learning
- Video data annotation for machine learning (Recorded tape from CCTV or camera, usually divided into scenes)
When compared with images, video is a more complex form of data that demands a bigger effort to annotate correctly. To put it simply, a video consists of different frames which can be understood as pictures. For example, a one-minute video can have thousands of frames, and to annotate this video, one must invest a lot of time.
One outstanding feature of video annotation in the Artificial Intelligence and Machine Learning model is that it offers great insight into how an object moves and its direction.
A video can also inform whether the object is partially obstructed or not while image annotation is limited to this.

Video data annotation for machine learning
- Text data annotation for machine learning: Different types of documents include numbers and words and they can be in multiple languages.
Algorithms use large amounts of annotated data to train AI models, which is part of a larger data labeling workflow. During the annotation process, a metadata tag is used to mark up the characteristics of a dataset. With text annotation, that data includes tags that highlight criteria such as keywords, phrases, or sentences. In certain applications, text annotation can also include tagging various sentiments in text, such as “angry” or “sarcastic” to teach the machine how to recognize human intent or emotion behind words.
The annotated data, known as training data, is what the machine processes. The goal? Help the machine understand the natural language of humans. This procedure, combined with data pre-processing and annotation, is known as natural language processing, or NLP.
Text data annotation for machine learning
- Audio data annotation for machine learning: They are sound records from people having dissimilar demographics.
As the market is trending with Voice AI Data Annotation for machine learning, LTS Group provides top-notch service in annotating voice data. We have annotators fluent in languages.
All types of sounds recorded as audio files can be annotated with additional keynotes and suitable metadata. The Cogito annotation team is capable of exploring the audio features and annotating the corpus with intelligent audio information. Each word in the audio is carefully listened to by the annotators in order to recognize the speech correctly with our sound annotation service.
The speech in an audio file contains different words and sentences that are meant for the listeners. Making such phrases in the audio files recognizable to machines is possible, by using a special data labeling technique while annotating the audio. In NLP or NLU, machine algorithms for speech recognition need audio linguistic annotation to recognize such audio.
Audio data annotation facilitates various real-life AI applications. A prime example is the application of an AI-powered audio transcription tool that swiftly generates accurate transcripts for podcast episodes within minutes.

Audio data annotation for machine learning
- 3D Sensor data annotation for machine learning: 3D models generated by sensor devices.
No matter what, money is always a factor. 3D-capable sensors greatly vary in build complexity and accordingly – in price, ranging from hundreds to thousands of dollars. Choosing them over the standard camera setup is not cheap, especially given that you would usually need multiple units in order to guarantee a large enough field of view.

3D sensor data annotation for machine learning
Low-resolution data annotation for machine learning
In many cases, the data gathered by 3D sensors are nowhere as dense or high-resolution as the one from conventional cameras. In the case of LiDARs, a standard sensor discretizes the vertical space in lines (the number of lines varies), each having a couple of hundred detection points. This produces approximately 1000 times fewer data points than what is contained in a standard HD picture. Furthermore, the further away the object is located, the fewer samples land on it, due to the conical shape of the laser beams’ spread. Thus the difficulty of detecting objects increases exponentially with their distance from the sensor.”
Step 2: Problem Identification
Knowing what problem you are dealing with will help you to decide the techniques you should use with the input data. In computer vision, there are some tasks such as:
- Image classification: Collect and classify the input data by assigning a class label to an image.
- Object detection & localization: Detect and locate the presence of objects in an image and indicate their location with a bounding box, point, line, or polyline.
- Object instance / semantic segmentation: In semantic segmentation, you have to label each pixel with a class of objects (Car, Person, Dog, etc.) and non-objects (Water, Sky, Road, etc.). Polygon and masking tools can be used for object semantic segmentation.
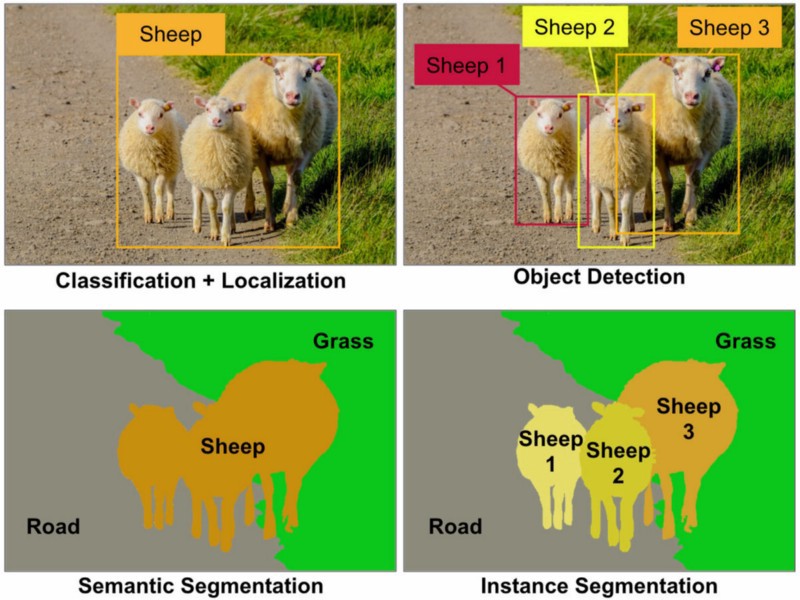
Step 3: Data Annotation for Machine Learning
After identifying the problems, now you can process the data labeling accordingly. With the classification task, the labels are the keywords used during finding and crawling data. For instance segmentation task, there should be a label for each pixel of the image. After getting the label, you need to use tools to perform image annotation (i.e. to set labels and metadata for images). The popular annotated data tools can be named Comma Coloring, Annotorious, and LabelMe.
However, this way is manual and time-consuming. A faster alternative is to use algorithms like Polygon-RNN ++ or Deep Extreme Cut. Polygon-RNN ++ takes the object in the image as the input and gives the output as polygon points surrounding the object to create segments, thus making it more convenient to label. The working principle of Deep Extreme Cut is similar to Polygon-RNN ++ but it allows up to 4 polygons.

Process of data annotation for machine learning
It is also possible to use the “Transfer Learning” method to label data, by using pre-trained models on large-scale datasets such as ImageNet, and Open Images. Since the pre-trained models have learned many features from millions of different images, their accuracy is fairly high. Based on these models, you can find and label each object in the image. It should be noted that these pre-trained models must be similar to the collected dataset to perform feature extraction or fine-turning.
Types of Annotation Data
Data Annotation for machine learning is the process of labeling the training data sets, which can be images, videos, or audio. Needless to say, AI Annotation is of paramount importance to Machine Learning (ML), as ML algorithms need (quality) annotated data to process.
In our AI training projects, we use different types of annotation. Choosing what type(s) to use mainly depends on what kind of data and annotation tools you are working on.
- Bounding Box: As you can guess, the target object will be framed by a rectangular box. The data labeled using bounding boxes are used in various industries, mostly in automotive vehicle, security, and e-commerce industries.
- Polygon: When it comes to irregular shapes like human bodies, logos, or street signs, to have a more precise outcome, Polygons should be your choice. The boundaries drawn around the objects can give an exact idea about the shape and size, which can help the machine make better predictions.
- Polyline: Polylines usually serve as a solution to reduce the weakness of bounding boxes, which usually contain unnecessary space. It is mainly used to annotate lanes on road images.
- 3D Cuboids: The 3D Cuboids are utilized to measure the volume of objects which can be vehicles, buildings, or furniture.
- Segmentation: Segmentation is similar to polygons but more complicated. While polygons just choose some objects of interest, with segmentation, layers of alike objects are labeled until every pixel of the picture is done, which leads to better results of detection.
- Landmark: Landmark annotation comes in handy for facial and emotional recognition, human pose estimation, and body detection. The applications using data labeled by landmarks can indicate the density of the target object within a specific scene.

Types of data annotation for machine learning
Popular Tools of Data Annotation for Machine Learning
In machine learning, data processing, and analysis are extremely important, so I will introduce to you some Tools for annotating data to make the job simpler:
- Labelbox: Labelbox is a widely used platform that supports various data types, such as images, text, and videos. It offers a user-friendly interface, project management features, collaboration tools, and integration with machine learning pipelines.
- Amazon SageMaker Ground Truth: Provided by Amazon Web Services, SageMaker Ground Truth combines human annotation and automated labeling using machine learning. It’s suitable for a range of data types and can be seamlessly integrated into AWS workflows.
- Supervisely: Supervised focuses on computer vision tasks like object detection and image segmentation. It offers pre-built labeling interfaces, collaboration features, and integration with popular deep-learning frameworks.
- VGG Image Annotator (VIA): Developed by the University of Oxford’s Visual Geometry Group, VIA is an open-source tool for image annotation. It’s commonly used for object detection and annotation tasks and supports various annotation types.
- CVAT (Computer Vision Annotation Tool): CVAT is another popular open-source tool, specifically designed for annotating images and videos in the context of computer vision tasks. It provides a collaborative platform for creating bounding boxes, polygons, and more.

Popular data annotation tools
When selecting a data annotation for machine learning tool, consider factors like the type of data you’re working with, the complexity of annotation tasks, collaboration requirements, integration with your machine learning workflow, and budget constraints. It’s also a good idea to try out a few tools to determine which one best suits your specific needs.
it is crucial for businesses to consider the top 5 annotation tool features to find the most suitable one for their products: Dataset management, Annotation Methods, Data Quality Control, Workforce Management, and Security.
Who can annotate data?
The data annotators are the ones in charge of labeling the data. There are some ways to allocate them:
In-house Annotating Data
The data scientists and AI researchers in your team are the ones who label data. The advantages of this way are easy to manage and has a high accuracy rate. However, it is such a waste of human resources since data scientists will have to spend much time and effort on a manual, repetitive task.
In fact, many AI projects have failed and been shut down, due to the poor quality of training data and inefficient management.
In order to ensure data labeling quality, you can check out our comprehensive Data annotation best practices. This guide follows the steps in a data annotation project and how to successfully and effectively manage the project:
- Define and plan the annotation project
- Managing timelines
- Creating guidelines and training workforce
- Feedback and changes
Outsourced AI Annotations Data
You can find a third party – a company that provides data annotation services. Although this option will cost less time and effort for your team, you need to ensure that the company commits to providing transparent and accurate data.
Online Workforce Resources for Data Annotation
Alternatively, you can use online workforce resources like Amazon Mechanical Turk or Crowdflower. These platforms recruit online workers around the world to do data annotation. However, the accuracy and the organization of the dataset are the issues that you need to consider when purchasing this service.
The Bottom Line
The data annotation for machine learning guide described here is basic and straightforward. To build machine learning, besides data scientists who will set the infrastructure and scale for complex machine learning tasks, you still need to find data annotators to label the input data. Lotus Quality Assurance provides professional data annotation services in different domains. With our quality review process, we commit to bringing a high-quality and secure service. Contact us for further support!
Our Clients Also Ask
What is data annotation in machine learning?
Data annotation in machine learning refers to the process of labeling or tagging data to create a labeled dataset. Labeled data is essential for training supervised machine learning models, where the algorithm learns patterns and relationships in the data to make predictions or classifications.
How many types of data annotation for machine learning?
Data Annotation for machine learning is the procedure of labeling the training data sets, which can be images, videos, or audio. In our AI training projects, we utilize diverse types of data annotation. Here are the most popular types: Bounding Box, Polygon, Polyline, 3D Cuboids, Segmentation, and Landmark.
What are the most popular data annotation tools?
Here are some popular tools for annotating data: Labelbox, Amazon SageMaker Ground Truth, CVAT (Computer Vision Annotation Tool), VGG Image Annotator (VIA), Annotator: ALOI Annotation Tool, Supervisely, LabelMe, Prodigy, etc.
What is a data annotator?
A data annotator is a person who adds labels or annotations to data, creating labeled datasets for training machine learning models. They follow guidelines to accurately label images, text, or other data types, helping models learn patterns and make accurate predictions.
